Introduction
“With Ising, AI becomes the control plane — the operating system of quantum machines — transforming fragile qubits to scalable and reliable quantum-GPU systems.” That is Jensen Huang announcing NVIDIA Ising on April 14, 2026 (NVIDIA, 2026a). Read it again, and strip out the word quantum. What is left is a description of the last fifteen years of enterprise infrastructure: a control plane, an operating system, an abstraction layer sitting on top of hardware the operators would rather not touch directly.
This article is not about quantum computing. It is about what NVIDIA’s announcement signals for the people who design, provision, and operate data centers — the architects who care about rack power, interconnect roadmaps, and which middleware stack their HPC team will ask them to support in 2029. The quantum physics underneath Ising is not the interesting part for that audience. The pattern is. NVIDIA is positioning AI as the operational layer for a class of hardware most enterprises do not yet own, and it is doing so using the same open-source, vendor-neutral playbook that made CUDA unavoidable a decade ago.
What NVIDIA Ising Actually Is
Ising is a family of open-source AI models for two specific quantum engineering problems: processor calibration and error-correction decoding (NVIDIA, 2026a). The family has two members.
Ising Calibration is a 35-billion-parameter vision-language model fine-tuned to read experimental measurements off a quantum processing unit and infer the tuning adjustments the hardware needs (NVIDIA Developer, 2026). Paired with an agent, it reduces calibration cycles from days to hours. On the QCalEval benchmark NVIDIA introduced alongside the release, the 35B model outperforms Gemini 3.1 Pro, Claude Opus 4.6, and GPT 5.4 on quantum calibration tasks (NVIDIA Developer, 2026; NVIDIA Research, 2026a).
Ising Decoding is a pair of 3D convolutional neural networks — 0.9M and 1.8M parameters, tuned respectively for speed and accuracy — that perform pre-decoding for surface-code quantum error correction (NVIDIA Research, 2026b). NVIDIA benchmarks it against pyMatching, the open-source decoder that most of the research community currently deploys, and reports 2.5x faster inference and 3x higher accuracy while requiring an order of magnitude less training data (NVIDIA, 2026a).
Both models are released under Apache 2.0 on HuggingFace, GitHub, and build.nvidia.com. Both integrate with CUDA-Q, NVIDIA’s hybrid classical-quantum programming platform, and with NVQLink, the QPU-GPU interconnect NVIDIA introduced in late 2025 (NVIDIA Developer, 2026). Early adopters named in the announcement include Fermilab, Harvard’s Paulson School, Lawrence Berkeley’s Advanced Quantum Testbed, the UK National Physical Laboratory, and quantum vendors IQM and Infleqtion (NVIDIA, 2026a). This is a platform play, not a science experiment.
The Pattern: AI as Operational Layer
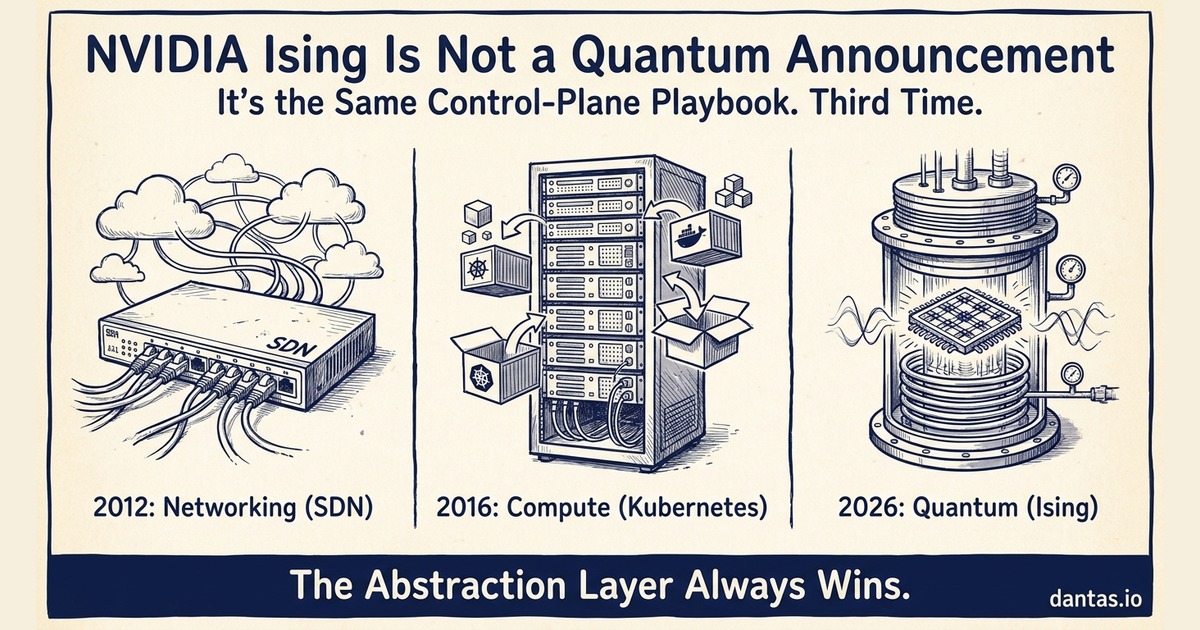
Anyone who sat through the SDN transition from 2012 onward recognizes what is happening here. Networking hardware did not get smarter. What changed was the location of the control logic. Forwarding tables used to be programmed in hardware by a closed, vendor-specific CLI. Then OpenFlow, and later the broader software-defined networking movement, pulled that logic into a software control plane that ran on commodity compute and spoke to the data plane through an open protocol. The ASIC did not disappear. It stopped being the integration point.
Kubernetes did the same thing to compute. Bare metal did not get more flexible. The scheduling, placement, and lifecycle decisions moved off the hypervisor and onto a declarative API, and every infrastructure decision above that API started being negotiated in YAML instead of in ticket queues. Enterprise architects who internalized that shift in 2016 and 2017 spent the next five years in demand. The ones who dismissed it as researcher toys spent the same five years explaining why their VMware estate could not do what the new hires expected.
NVIDIA is now executing the same move against quantum hardware. Qubits are fragile, noisy, and vendor-specific — superconducting, trapped-ion, neutral-atom, photonic. Every modality has its own calibration procedure and its own error profile. The traditional response to that heterogeneity would be a vertically integrated stack per vendor. NVIDIA is proposing the opposite: a horizontal control layer — CUDA-Q for orchestration, Ising for the ML-driven operational tasks, NVQLink for the physical interconnect — that treats the QPU as a pluggable accelerator behind a standardized software boundary (NVIDIA, 2026b).
This is the same bet that made CUDA the default for GPU compute even when AMD hardware was competitive on specs. Own the abstraction layer, make it open enough to be adopted, and the hardware underneath becomes interchangeable. Huang’s “operating system of quantum machines” is not a metaphor. It is a product strategy. For infrastructure architects, the lesson from the last two transitions is uncomfortable and consistent: the abstraction layer wins, and the teams that learn it first set the architectural vocabulary for everyone else.
Infrastructure Implications
Hybrid quantum-GPU racks are no longer a research slide. NVQLink exists as a low-latency interconnect specifically because error correction has to run on a classical accelerator faster than decoherence accumulates on the QPU — microseconds, not milliseconds (NVIDIA Developer, 2026). That is a physical-layer requirement. It implies co-located GPUs and QPUs sharing a rack or adjacent racks, with cooling profiles that combine cryogenic dilution refrigerators (millikelvin for superconducting qubits) and standard liquid-cooled GPU density. Power, floor loading, EMI isolation, and cable path engineering all move. This is not a 2030 problem. Early adopter sites are building these rooms now.
NVQLink is worth tracking the same way InfiniBand was worth tracking in 2008. It may not be the standard that wins, but it is the standard with the largest vendor pushing it, and its adoption curve will tell you which quantum vendors are playing in the NVIDIA ecosystem versus building their own closed stacks. For procurement and roadmap planning, that signal matters more than the qubit count in any given press release.
CUDA-Q is the middleware layer to learn. Not because every architect needs to write quantum kernels, but because CUDA-Q is where the orchestration model for hybrid jobs is being defined — how a workload schedules across classical GPUs, QPUs, and the AI models that sit between them. The parallel to learning Kubernetes primitives in 2017 is exact. Engineers who understood pods and services before they became interview table stakes had an unreasonable career advantage. CUDA-Q documentation is free; the time to read it is now.
The open-source release matters for a reason that tends to get lost in the coverage. Apache 2.0 licensing on both Ising models means enterprises can retrain them on proprietary QPU telemetry without surrendering the data to a vendor cloud (NVIDIA, 2026a). For regulated industries — pharma, defense, finance — this is the difference between a quantum roadmap that is viable and one that dies in legal review. It is also the answer to the reflexive concern about NVIDIA lock-in: the models are open, the weights are open, the training framework is open. What NVIDIA owns is the interconnect and the orchestration layer, which is exactly where it has always made its money.
What Enterprise Architects Should Actually Do Now
The actionable list is short and deliberately unglamorous.
Read the CUDA-Q documentation and the Ising Calibration model card on HuggingFace (NVIDIA, 2026b; NVIDIA Developer, 2026). Not to implement anything. To calibrate your own mental model of where the abstraction boundaries are being drawn. A two-hour reading session will put you ahead of 95% of your peers.
Track NVQLink adoption announcements across the quantum vendor landscape — IQM, Infleqtion, Quantinuum, PsiQuantum, IonQ. The ones that integrate are joining an ecosystem with gravitational pull. The ones that do not are making a different bet that may or may not pay off.
Start an internal conversation with your HPC, research, or advanced-engineering team about quantum readiness. Not a budget request. Not a vendor evaluation. An awareness conversation. The question is: if one of our research workloads became viable on a hybrid quantum-classical system in three years, what would our data center need to change? The answer will expose whatever gaps exist in cooling, interconnect, and skill coverage, and those gaps take years to close.
What not to do: do not panic-buy quantum roadmap consulting, do not commit capex to qubit-count milestones that have no connection to your workload, and do not let a vendor sell you a “quantum-ready” anything. The QED-C 2026 industry report projects the quantum computing market at roughly $3 billion by 2028 — real, growing, but still two orders of magnitude below enterprise AI infrastructure spend (QED-C, 2026). This is a watch-and-learn phase, not a procurement phase.
Youtube
Conclusion
NVIDIA Ising is not a quantum computing announcement dressed up as an AI announcement. It is an infrastructure announcement about where the control plane of a future hardware class is being built, and who is building it. The pattern is one enterprise architects have lived through twice already — in networking and in compute — and the lesson from both is that the abstraction layer, once it becomes open enough to adopt, decides the shape of the ecosystem. The qubits will do what qubits do. The interesting architectural question is what sits between them and your workload, and NVIDIA has just told you what it thinks the answer is.

References
NVIDIA. (2026a, April 14). NVIDIA launches Ising, the world’s first open AI models to accelerate the path to useful quantum computers [Press release]. https://nvidianews.nvidia.com/news/nvidia-launches-ising-the-worlds-first-open-ai-models-to-accelerate-the-path-to-useful-quantum-computers
NVIDIA. (2026b). Open AI models for quantum computing: NVIDIA Ising. NVIDIA Developer. https://developer.nvidia.com/ising
NVIDIA Developer. (2026, April 14). NVIDIA Ising introduces AI-powered workflows to build fault-tolerant quantum systems. NVIDIA Technical Blog. https://developer.nvidia.com/blog/nvidia-ising-introduces-ai-powered-workflows-to-build-fault-tolerant-quantum-systems/
NVIDIA Research. (2026a, April). QCalEval: Benchmarking vision-language models on quantum calibration plot interpretation. https://research.nvidia.com/publication/2026-04_qcaleval-benchmarking-vision-language-models-quantum-calibration-plot
NVIDIA Research. (2026b, April). Fast AI-based pre-decoders for surface codes. https://research.nvidia.com/publication/2026-04_fast-ai-based-pre-decoders-surface-codes
NVIDIA. (2026c). Ising-Calibration-1-35B-A3B [Model card]. HuggingFace. https://huggingface.co/nvidia/Ising-Calibration-1-35B-A3B
Quantum Economic Development Consortium. (2026, April 14). State of the global quantum industry 2026. https://quantumconsortium.org/publication/2026-state-of-the-global-quantum-industry-report/